

Close to launching a new game? Have the platform Gods promised you visibility on their stores? Trying to predict the install volume that visibility is going to get? If you’re looking for an exact number, you should probably turn to a crystal ball. But, if you’re looking for a range, do read on!
Editor’s note: This is a guest post by Abhimanyu and Victoria first posted on Deconstructor of Fun. The work showcased here was performed during their time at Flaregames.
It has become clear to many that install volumes delivered through featurings (iOS more so) are not as strong as they used to be. But prominent store visibility still delivers significant traffic and companies do plan for the future with this in mind. Unfortunately, trying to predict featuring week/month install volumes plagues many teams. Not surprisingly, it is also one of the most critical and hardest jobs for PMs/Executives to do when trying to justify a project’s revenue forecast. Every company solves for it differently, with most defaulting to looking at similar games and coming up with an estimate. But accuracy rates are poor and opinions can sway interpretations with such methodologies.
Acknowledging this problem’s difficult nature and no publically available analysis around the topic, we set out to bring some science to a seemingly abstract prediction problem. By focussing on key factors a potential customer might consider before making a download decision, we decided to test the following hypothesis – “A relationship exists between a game’s launch week install volume and it’s Featuring Placement, Genre and Art Style”. The analysis below confirms this hypothesis as True. And through this article, we’d like to open up our methodology for companies to put into practice and associated findings for the industry to further build on.


Analysis Methodology
As with any exercise of this nature, the analysis methodology included the steps of dataset building, statistical testing and model generation.
More specifically –
- 150+ games featured between April 2nd and September 27th 2018 were analyzed
- Each game was categorised by Featuring Placement, Genre and Art Style
- The Kruskal-Wallis (KW) Hypothesis Test was used to test the hypothesis
- A linear regression model was built, that takes a hypothetical game’s 3 variable classification as input, and outputs an expected launch week/month install volume range
For base dataset building, we used App Annie’s excellent service offerings to collect iOS organic install estimates and featuring dates for the games analysed. It was also assumed that the worldwide iOS featuring date coincided with the iOS US featuring date. Consequently, the analysis is limited to iOS data.
Paid games and featured games with major IPs were not considered in the base dataset. Major IP games includes (but not limited to) games based on major motion pictures, TV series, famous people and sequels to original hits. It should be mentioned that we did attempt to include major IP games in the first analysis run, but slowly realised that it is a beast to decipher. It was concluded that the number of factors contributing to launch week/month install volumes for major IP games is out of the scope of this analysis. But, we plan to tackle this problem in the future by building on the work here.
Variable Definitions
Each game in the data set was classified according to 3 variables – Featuring Placement, Genre and Art Style. Associated values with these look like this:

For Genre, we used a brilliant genre taxonomy developed by Game Refinery and Michail Katkoff (see below). For example, “Casual” is a Category, “Arcade” is a Genre and “Platformer” is a Sub-genre. Sub-genres were not considered for data point classification purposes, since the base dataset was limited and intricate classification would not yield actionable learnings. Though, it should be noted that Sub-genres can definitely be used for larger data sets.

Proving the Hypothesis
To restate the initial hypothesis – “A relationship exists between a game’s launch week install volume and it’s Featuring Placement, Genre and Art Style”.
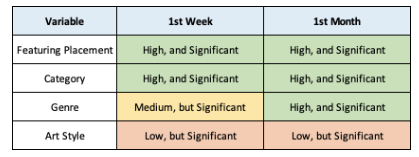

Using the Kruskal-Wallis (KW) Hypothesis Test, the above hypothesis was confirmed as True. The hypothesis was further extended to prove a similar relationship with launch month install volumes. The table below summarizes the significance of each test through a p-value, which should be below 0.10 to be statistically significant. Overall each variable showed statistical significance with various strengths. Here is a summary of our findings –
While “Art Style” is definitely the weakest of the lot, it is expected to achieve a stronger relationship as the base dataset size keeps increasing. The same with “Genre”. At the same time, it is important to note that a significant result is quite relevant, regardless of the strength of it.
Given the relationship table above, next we set out to –
- Build install ranges for each one of the variable values
- Build a model that utilises these variables in different intensities to provide a directional forecast on where a hypothetical game’s launch week/month install volume would lie
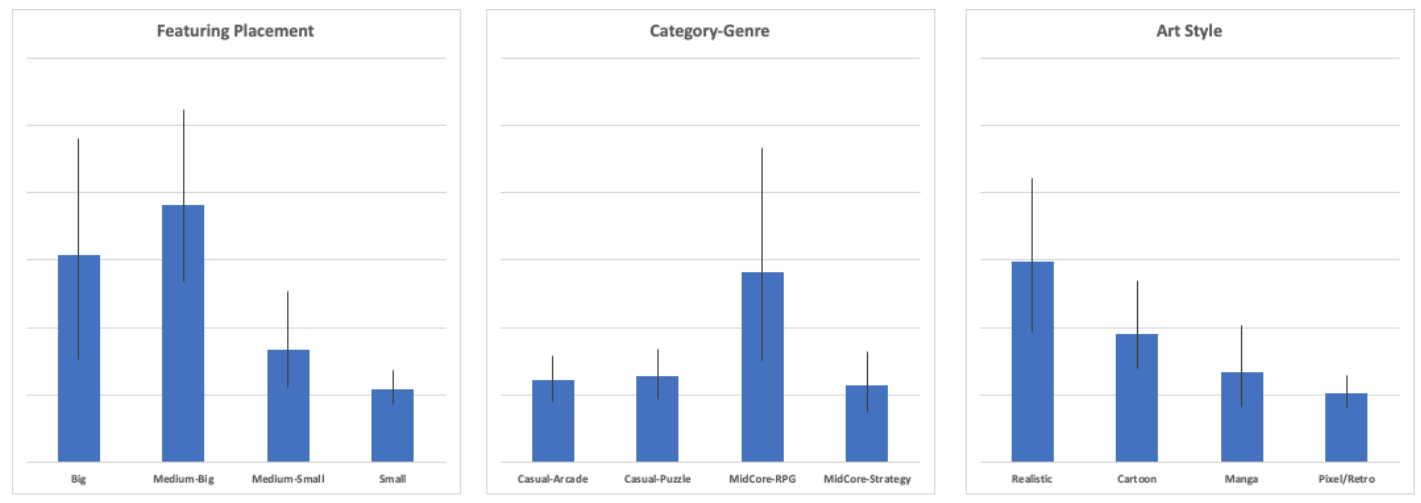
Given below is a visualisation of launch week install ranges for some values of the variables. The blue bars represent averages, while the black lines represent a sensitivity range. One interesting observation is how a “Big” featuring does not necessarily translate into a higher launch week install volume range compared to a “Medium-Big” featuring, which further supports the fact that there are more variables at play when deciding to download a game.

Can We Now Look into the Future?
The obvious next step from the above analysis was to build a model that provides a directional forecast of launch week/month install volume ranges for hypothetical/unreleased games. It should be called out that a base dataset of 150+ games is not large enough to create stable predictive models. Though one can attempt it by taking a few pragmatic liberties.
Our attempt centered around creating a simple linear regression model using the 3 variables as inputs, and testing it against featured games that were not considered in the base dataset. The hope was to retrieve results that would justify building a complex statistical model, and we were happy to see some results that would justify an additional time investment. Given below is a comparison between predicted launch week install volume from our model and the actuals according to App Annie download estimates-
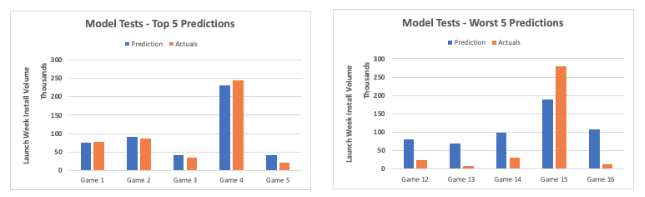
As seen above, we had our share of good and bad predictions with an average difference range of +/-50k. This is mostly driven by a very primitive model design first, and a small base dataset second. Most definitely, there is further accuracy upside to be gained by trying out different and maybe more complex statistical models while simultaneously increasing the size of the base dataset. Since it is very easy to over invest in such an effort, finding a balance between model design complexity and time investment is key and should be driven by the goals these directional forecasts are meant to achieve.
Methodology for Predicting Launch Week Installs Effectively
Given the above work, it is clear that a relationship exists between launch week/month installs and featuring placement, genre and art style. To build on the work here, we’d look to find stronger relationships by continuing to grow our data set, trying out more complex statistical models and also considering a few more key variables like IP, platform, theme, app size and launch market.
We can also confidently say that when it comes to predicting your launch week/month installs, one should stick to directionality and play with ranges rather than boiling the ocean to find the one right number. Hopefully the methodology and findings above add to your toolkit for better business planning!





